AI Still Struggles with Human Social Understanding, Johns Hopkins Study Finds
Published: April 24, 2025
Despite remarkable progress in object recognition and language understanding, artificial intelligence models still fall short when it comes to interpreting human social interactions in dynamic scenes, according to a new study by Johns Hopkins University researchers.
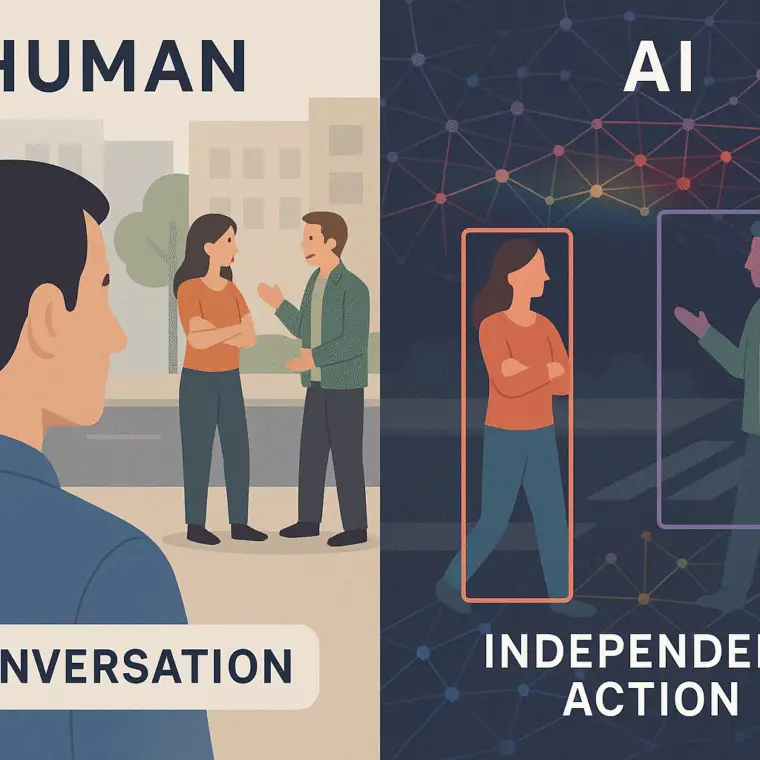
“AI systems struggle to determine basic human cues such as identifying who is speaking, predicting when a person will cross the street, or recognizing simple conversational engagement,” reports ScienceDaily.
These findings, also highlighted in INDIA New England News, cast doubt on the readiness of AI for autonomous roles that demand real-time social awareness, such as self-driving vehicles or assistive robots.
The Study
The investigation was led by Dr. Leyla Isik, cognitive scientist at Johns Hopkins, along with Kathy Garcia, a doctoral student in her lab. The research was presented at the International Conference on Learning Representations (ICLR) in Singapore, underlining its importance to the machine learning community (The Hub, ScienceDaily).
The researchers argue that the social-understanding gap may arise from current AI architectures, which are modeled after neural networks optimized for static images not contextual, real-world interactions (The Hub, ScienceDaily).
Methodology
More than 150 human participants were shown three-second video clips of various social scenarios people interacting, performing parallel activities, or acting alone and asked to rate key social features on a five-point scale (INDIA New England News, ScienceDaily).
Researchers then tested 350+ AI models from across language, video, and image domains. These models were tasked with predicting:
Human ratings for each clip
Neural response patterns based on text descriptions
The models included:
Large language models (text-based)
Video models (motion sequences)
Image models (still frames)
(The Hub, ScienceDaily, INDIA New England News)
Key Findings
Human participants showed high consistency in their understanding of the scenes, indicating a shared sense of social dynamics. AI models, however, failed to match these judgments, regardless of size or training (ScienceDaily, INDIA New England News).
Video models performed poorly at identifying interactions, frequently misclassifying conversational engagement as independent activity.
Image models often failed at even simple scene understanding when only still frames were provided.
Large language models fared slightly better in predicting human judgments of behavior.
Video models showed some capability in predicting neural activity, suggesting complementary strengths across modalities.
(The Hub, ScienceDaily)
Implications for Real-World AI
These limitations raise concerns about deploying AI in environments where social-cue interpretation is critical:
Self-driving cars need to interpret pedestrian behavior accurately (Bloomberg Law).
Assistive robots in healthcare and hospitality must read body language and conversational tone (INDIA New England News).
On manufacturing floors, robots must anticipate human movements to ensure team coordination and safety (Bloomberg Law).
Charting the Path Forward
Experts argue that future AI systems must:
Move beyond static-image-based architectures
Integrate motion-sensitive processing modules
Leverage context-aware memory
Adopt multimodal fusion strategies
(The Hub, ScienceDaily)
Additionally, AI training datasets need to include more richly annotated, dynamic social interactions to help models generalize better in real-world applications (INDIA New England News, ScienceDaily).
Conclusion
While AI continues to excel in object recognition and language processing, this study highlights a critical human capability AI lacks: the ability to interpret social context in motion.
“Good news: the robots aren’t taking over just yet.” INDIA New England News
For now, human judgment remains indispensable in fields requiring nuanced social perception.